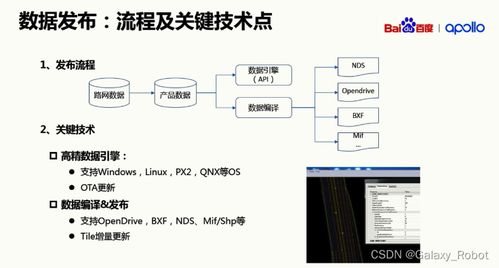
MapReduce分布式计算框架 分而治之思想与软硬件技术支撑
《Hadoop/Spark大数据技术(微课版)》(曾国荪、曹洁 编著)第三章深入剖析了MapReduce这一经典的分布式计算框架。本章内容的核心在于理解其设计思想与实现机制,其中“分而治之”是灵魂,而计算机软硬件技术则是其得以高效运行的坚实基石。
一、核心思想:分而治之
MapReduce框架的核心设计哲学正是古老的“分而治之”(Divide and Conquer)策略在现代大规模数据计算场景下的完美体现。这一思想贯穿于计算任务处理的始终:
- “分”(Map阶段):
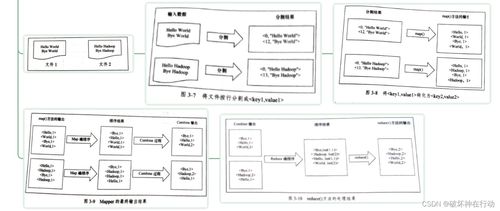
- 数据分片:框架首先将海量的输入数据自动切割成多个独立、大小适宜的数据块(Split),这些数据块被分布式地存储在不同的计算节点上。
- 任务分发:系统为每个数据分片创建一个Map任务,并将其调度到存储有该数据分片副本的节点上执行,实现了“计算向数据迁移”,极大减少了数据网络传输开销。
- 并行处理:每个Map任务独立地处理一小部分数据,读取输入分片,调用用户定义的Map函数,输出一系列中间键值对。成千上万个Map任务可以并行运行,这是处理速度得以飞跃的关键。
- “治”(Reduce阶段):
- 洗牌与排序:框架会自动将Map阶段输出的所有中间键值对,按照键(Key)进行重新分发与排序,确保所有相同键的数据都被汇集到同一个Reduce任务进行处理。这个过程称为“Shuffle”,是连接Map和Reduce的桥梁。
- 归约汇总:每个Reduce任务接收针对某一组键的所有中间值,调用用户定义的Reduce函数,对这些值进行归约、汇总、过滤或其他计算,最终生成最终的输出结果。
通过“分而治之”,一个庞大的、看似无法单机处理的计算问题,被分解为大量可并行执行的细小任务,再将其结果合并,从而高效地解决了大数据计算的难题。
二、计算机软硬件技术的深度开发与支撑
MapReduce框架的落地与高效运行,离不开底层一系列计算机软硬件技术的深度开发和协同工作。书中第三章也着重探讨了这一层面的支撑:
- 硬件技术基础:
- 廉价商用硬件集群:MapReduce设计之初就面向由普通PC服务器组成的集群,而非依赖昂贵的大型机或专用设备。这得益于现代多核CPU、大容量硬盘和高速网络等硬件的普及与性能提升。
- 分布式存储(HDFS):作为MapReduce的“孪生兄弟”,HDFS提供了高可靠、高吞吐量的数据存储服务。它将大文件分块存储在多台机器上,并通过多副本机制保证容错,这直接为Map阶段“计算向数据迁移”提供了可能。
- 软件系统与核心开发:
- 资源管理与调度(YARN):在Hadoop 2.0之后,YARN作为统一的资源管理平台,负责整个集群的计算资源(CPU、内存)管理和任务调度。它将JobTracker的功能拆分为ResourceManager和ApplicationMaster,使得MapReduce作业的调度更加高效、灵活,并支持多种计算框架共存。
- 容错机制:这是MapReduce框架软件设计的精髓。通过任务级别的容错(失败的任务会被自动重新调度到其他节点执行)、数据冗余存储(HDFS多副本)以及推测执行(对“慢任务”启动备份任务)等机制,框架能够在由成千上万不稳定节点组成的大规模集群中稳定运行。
- 数据本地化优化:调度器会优先将Map任务分配给存储有输入数据块的节点,这一软件的优化策略极大地减少了集群网络带宽的压力,提升了整体性能。
- 序列化与RPC通信:框架内部定义了紧凑、高效的序列化机制(如Writable接口),用于节点间的数据传输;基于RPC的通信模型保障了各个组件间稳定可靠的远程调用。
###
第三章的思维导图清晰地勾勒出MapReduce的双重脉络:在顶层,是清晰优雅的“分而治之”计算模型,它简化了分布式编程的复杂度;在底层,则是一整套针对大规模商用硬件集群深度开发的、复杂而精妙的软件系统技术。正是这种“简单接口”与“复杂实现”的结合,使得MapReduce成为大数据时代第一个得以广泛应用和验证的分布式计算范式,并为后续如Spark等更高效框架的出现奠定了坚实的思想和技术基础。理解这一章,不仅在于掌握MapReduce的工作流程,更在于领悟如何利用软硬件技术将一种强大的计算思想工程化、落地化。
如若转载,请注明出处:http://www.iceftech.com/product/57.html
更新时间:2026-06-19 23:15:13